If you follow me on Twitter, then you might have noticed that I’ve been fighting a lot of fires lately. Between high CPU (several times 1, 2), blocking queries, a slow failover, and deadlocks there have been a ton of things that needed attention. Not all of these issues are interesting to people, but one of them might be…the deadlocks. I’m going to go into details about what deadlocks we hit, why we hit them, and how we resolved them.
Background
A few years ago, we launched Stack Overflow for Teams, which allows you to have a private version of Stack Overflow to share knowledge. I haven’t written about the infrastructure of Teams, but my colleague, Dean Ward, gave a presentation about how Stack Overflow for Teams was built - it’s good, go watch it.
Here’s a brief overview of what we have on the SQL Server side - we have a 3 server cluster for Teams (2 in NY, 1 in CO) that are using Always On Availability Groups. We use schemas to keep teams separated from each other, and we put 10,000 schemas in each database, so we have multiple databases with 10,000 schemas in each one.
Managing Schemas
When we started Stack Overflow for Teams, we manually provisioned each new team (yeah, I know) - this meant someone ran a script to create the login, user, schema, tables, and then granted the necessary permissions for the schema user. Even though we joked about it, manually provisioning new teams wasn’t scalable and didn’t last long, so we came up with a process to pre-provision everything needed for a new team to start.
We never wanted to run into a race condition or incur the performance overhead with setting up a new team, so we pre-provisioned a set number of schemas that would be ready when someone signed up. The pre-provisioned teams would be already set up with
- Login
- User
- Schema
- Permissions
- Tables, Views, and any other database objects
Initially, we had about 100 schemas ready to go, and then had a scheduled job that would check periodically to refresh our provisioned bucket and replenish it back to full. We realized very quickly that 100 schemas wasn’t enough because we constantly hit issues with the logins not being available on the secondary replicas, so we decided to increase the provisioned pool to 500. For the last several years, a pool of 500 schemas worked great, until it didn’t.
The Launch of Free Teams
As expected, with the announcement that Stack Overflow for Teams is free for up to 50 users, we saw an incredible spike in sign-ups. Along with the spike in sign-ups, I started to receive a huge increase in alerts about deadlocks on the primary SQL Server for Teams. In the two weeks it took us to resolve the deadlocks, we hit at least 200 deadlocks.
What Is A Deadlock?
A deadlock occurs when two processes want access to the same resource. The first one has a lock on a resource, and the second process wants the same access, or vice versa. Since the processes are competing for the same resource, the result is a situation where one process needs to terminate so the other can continue.
Time to Investigate
Most people who manage a highly transactional database are probably familiar with deadlocks, or have seen them pop up every now and then. We had them in the past when provisioning schemas, but it was long ago and we thought the issue was over.
But, after the launch of free teams, I was receiving a deadlock email alert every few hours from SQL Sentry. While these email alerts provided some details into the issue, I needed to dig in further to figure out what exactly was happening, and try to resolve it. Thankfully, I have a handful of tools at my disposal to help investigate what we were seeing.
Between SQL Sentry and Brent Ozar’s sp_BlitzLock, I was able to get more details on each deadlock, including what the victim was, what type of locks we were hitting, and the processes involved in each deadlock.
The query text of the victim was pretty much same each time. As you can see, it wasn’t very helpful, as the victim was always when another process was just trying to set the transaction level (or at least that’s all the text we ever captured):
The other query involved in the deadlock was also basically same each time:
|
|
And the deadlock graph for each one was always the same, but it provided a critical piece of information that we needed - the lock type:
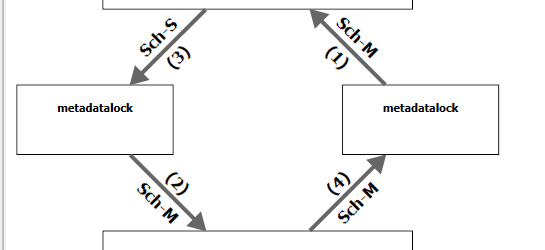
The dreaded Sch-M lock. I knew about the evils of this lock from Michael J Swart, but we had never faced it to this level before.
Every deadlock we hit was due to the permission GRANT during provisioning. Even if the victim query was on a completely different schema, the Sch-M lock taken by the permission grant always won.
Resolving the Deadlocks
Now that we identified the cause of the deadlock, it was time to figure out how to stop them. We brainstormed several ideas on how to fix it.
The scheduled job to replenish the pool of pre-provisioned teams runs every 5 minutes, so first we thought what if we spaced out that process? That wouldn’t work because all it would do is punt the problem to the new timeframe, which might potentially make it worse since we’d need to provision more schemas at a time. So, instead of the 5 - 15 we were provisioning every 5 minutes, we might need to create 50 or more if we waited an hour.
We also thought about provisioning a larger number of schemas, and then replenishing the pool nightly when we have less traffic, but again realized that it was just punting the problem - not actually fixing it.
Finally, we discussed pre-provisioning an entire database. That might work.
As I mentioned earlier, we put 10,000 schemas in a database, so the thinking was, if we set up a new database and provisioned the whole database with what we needed to start a team, then we no longer would hit the deadlocks by granting the permissions every 5 minutes. By setting up all the permissions ahead of time, the scheduled job would still need the Sch-M lock, but it would be taking it on a database not yet in use, hopefully removing its impact and the deadlocks.
The plan was to change the order in which we provisioned the new teams. We would pre-provision a new database with 10,000 logins, users, schemas, and their permissions, and would still keep our current bucket of 500 provisioned schemas that have the tables, views, and other database objects (the ones ready to go when a new team is created). Once we got close to using all of the schemas in a database, the pre-provision process would kick off on the next database and set up the next 10,000 schemas, removing the chances of getting deadlocks.
Dean Ward spent several days refactoring the code for the provisioning and when we pushed it out, it was time to create all the schemas and see if the deadlocks went away.
It worked.
We resolved the deadlock by refactoring the process so we weren’t taking the Sch-M lock for the permission grant every 5 minutes. By granting all the permissions ahead of time, we no longer have to fight with other processes and we stopped getting deadlocks.
Final Thoughts
Deadlocks are “fun” and can be complicated. This one was interesting because I had never seen a deadlock victim on setting the transaction isolation level, but once I saw the Sch-M lock it was clear we needed to do some refactoring of our process. Sch-M locks are definitely not fun, and if you need to take that lock on a heavily used database you might need to look at refactoring or even performing the work off hours.
Side Note
Oh, and while we did resolve the deadlocks, we also introduced an issue that none of us thought about until we started getting exceptions. The new refactored pre-provisioning process creates the login, user and schema, but when we move that schema to a provisioned state and we create the tables and database objects in the schema, we also change the password for the login. Our process to sync logins across our replicas didn’t account for those password changes which resulted in login failures, so we had to quickly resolve that issue after the change.
And by the way, if you’re interested, go sign up for a team, it’s free and it won’t generate a deadlock.